

Wrap Up & Materials of PARTHENOS eHumanities and eHeritage Webinar Series Webinar: Make it Happen – Carrying out Research and Analysing Data
written by Ulrike Wuttke, Carlo Meghini, George Bruseker (09.05.2018v1, 15.05.2018v2)
Trainers: George Bruseker (FORTH, Greece), Carlo Meghini (CNR, Italy), Moderator: Ulrike Wuttke (University of Applied Sciences Potsdam),
Date and Time: Thursday, 08.02.2018, 11:00 – 12:00 A.M. CEST
Materials
- View the slide set on SlideShare (PDF).
- Download the slide set from HAL (PDF).
- Download the slide set from Zenodo (PPTX).
- Watch the webinar recording on the PARTHENOS YouTube Channel.
- Watch the interactive webinar recording via Adobe Connect.
Wrap Up
This webinar was dedicated to the phases of the research lifecycle entitled “Carry out Research” & “Analyse Data”, particularly in the context of a research infrastructure. Carrying out research and analysis in the context of a research infrastructure, it was argued, requires a change in approach to research, where the on-going harmonization of data and interconnection of datasets together with the ability to access and employ interoperable services deploying relevant software tools is crucial.
The webinar was nearby sold out with 53 tickets out of 70. The participants joined the webinar from several European countries such as Austria, Greece, Germany, Denmark, the Netherlands, Russia etc.
The trainers, George Bruseker and Carlo Meghini, divided their engaging presentation into three parts:
- “Benefits and Challenges of Research Infrastructures for Researchesr”
- “Technical Challenges to Setting up an Effective Research Infrastructure and the PARTHENOS Proposition”
- “Step-by-Step of Research-Register-Research, On-demand Integration Cycle”
After a short introduction by George Bruseker, Carlo Meghini explained in the first section of the webinar what research infrastructures actually entail from an organizational point-of-view. He described a research infrastructure as a complex IT system, set up and constantly enriched by a research organization to provide its scientific community with digital resources for conducting research. He also told the participants about resources like data and knowledge and their correlation. Then Carlo used a poll to query the participants about their experiences with data, tools, and services. Most of the participants indicated their general satisfaction with the data, tools, and services that they have access to, but most of them also wished that these would be more easily discoverable and their wish to have more tools for data processing. After this Carlo explained the benefits and the problems of research in the context of a research infrastructure, tracking between the benefits of increased access and sharing to primary resources with the drawbacks of increased time and investment to produce quality, reusable and provenanced resources.

Results Poll 1: Are you happy with the data, tools and services you have access to?
The second part of the webinar was presented by George Bruseker who began this section with another poll. This poll dealt with the question of the percentage of their research time that participants devote to downloading, installing, configuring and maintaining IT tools and/or trying to understand and clean existing datasets for their research.
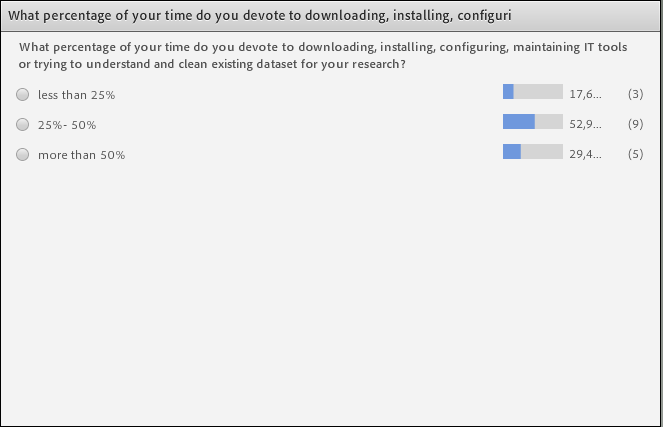
Results Poll 2: What percentage of time do you devote to downloading, installing, configuring, maintaining IT tools or trying to understand and clean existing datasets for your research?
The results of the, admittedly limited poll set, were highly interesting. Most of the participants chose the option 25%-50%, followed by a significant portion of participants who devoted more than 50% of their time. The trainers underlined the eye-opening nature of result, noting the considerable amount of time spent in this activity and the fact that even marginal gains of efficiency in this process, such as could be offered through well functioning RIs, would lead to large downstream benefits to researchers. After the poll, George introduced some of the basics of the technical challenges in setting up an RI. In particular he introduced the basic problem of data heterogeneity, indicating its cause in non-reducible factors including divergence in actors, objects, means and ends of research. He then introduced the typical solutions to this problem including the declaration of minimal or maximal data standards. he connected these methodologies to an unacknowledged bias towards the idea that the technical setup of a Research Infrastructure is an engineering task setup to deliver a ‘supermarket’ of data goods. In contradistinction to this typical approach he introduced the Parthenos approach to the task of information integration for Research Infrastructures. Instead of promoting/forcing yet another metadata standard on the research communities, Parthenos offers a semantic data model that allows the representation of research processes themselves in order to build a register of primary resources used by RIs. This register has the function of enabling a picture of the actual state-of-play of resources (data, software, services, actors, projects) at the present time and thus allows the planning and execution of specific integration taks targeted towards specific research goals. The overall architecture that is proposed suggests a register linked to a mapping facility and a platform that allows the creation of Virtual Research Environments (VREs) in which particular integrations of data, software and services from different RIs can be put together in order to create original research and enable a slowly developing, provenanced overall integration of resources.
In the last part of the presentation the trainers set out to describe the aspect of “mak(ing) it happen” with regards to the so-called ‘research phases’, indicating the generic research workflow in the context of a research infrastructure, referring to the research data cycle. They “walked” the participants along the following five steps: register initial resources, map major data structures to registry, determine useful integrations and map, setup VRE (Virtual Research Environment) and populate, and carry out research and register results. They concluded with an open answer poll where they asked the participants what they expect as chief benefits from a research infrastructure. There were three answers: access to data, knowledge sharing, and reproducible science.
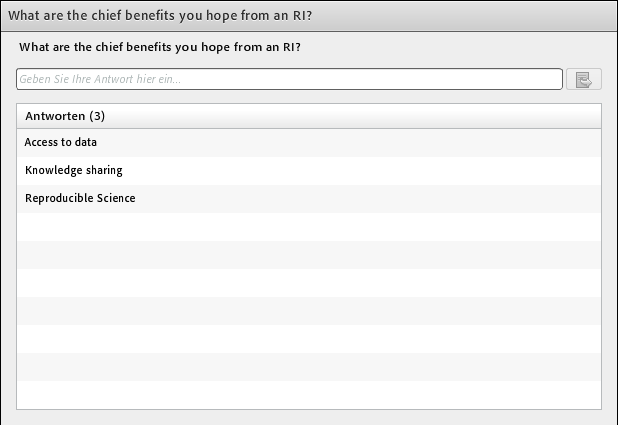
Results Poll 3: What are the chief benefits you hope from an RI?
Wrapping up, George and Carlo presented to the participants four key takeaway messages with regards to the challenges and benefits of carrying out research in an RI context:
- Share and Understand Priorities: the basic problems of setting up and accessing/ using an RI are shared aims and goals clearly stated and invested in
- Build the data foundations, build the knowledge foundations: research in an RI will not come about through a big bang where everything will be ready and available through some techno-utopia, data integration is an iterative, long term process that must be maintained and depends on a commitment to quality, reusable research
- From the foundations extend your knowledge through targeted VREs: deep integration of data and services to generate new knowledge requires dedicated infrastructure setup on the basis of the basic data integration of the register, this requires specialized knowledge and interdisciplinary collaboration between domain specialists and computer scientists inter alia
- slow but steady cross the infinite distance: building research programmes in an RI context that meet the kind of principles such as FAIR currently being promoted is not a one off process, it is a continuous and long term effort, like the scientific project itself
For those interested in the topics broached in this webinar and wishing to learn more, it was noted that George and the team at ICS-FORTh are preparing, together with the PARTHENOS WP7 training materials team, a new learning module about ontologies which will be launched in the second half of 2018. Moreover, additional information about research infrastructures prepared by PARTHENOS Training can be found in the module Introduction to Research Infrastructures, which features among others a short video with Kristen Schuster from King’s College London “Ontologies explained (in 5 minutes or less)”. Research Infrastructures were discussed from a less technical point of view in the PARTHENOS Webinar Beyond Tools by Stefan Schmunk and Steven Krauwer. PARTHENOS Training has also recently launched a module Manage, Improve and Open Up your Research and Data.
Summary of the Question & Answer Session
After Carlo and George had given their presentation, they answered live to questions the participants submitted to them. This discussion went in several interesting directions and is summarized below, with relevant links noted:
Jeff thanked for the very interesting presentation and explained that this was the first time he had heard of VREs (ad hoc project spaces) and that they seemed very useful to him. He indicated to have a look at D4Science and asked for additional resources for consultation.
Carlo answered that research infrastructures and VREs are very recent topics. These concepts will need some time to solidify, at the moment you will find many different definitions, depending on the scientific community. There are not yet monographs or other canonical readings (and they are seldomly thought in an academic context), therefore you will need to search for doctoral theses or articles from conferences. D4Science is a good starting point, more than 40 VREs are registered in D4Science at the time being.
Martina asked if there exists a registry of VREs or RIs (comparable to re3data.org for research data repositories)? George answered that this is what PARTHENOS aims to create for its sector and is currently building it, but it is not yet ready. A general registry does not exist to his knowledge.
Martina had commented during the presentation to the second poll that tools take less time and data take more time. George reacted to this as himself finding it true. He added that it concerns him that if people are already spending their time on data munging, they don’t do it in a reproducible way and not sharing it.
Slava: Can you please explain relation how VREs can keep provenance information on data and tools in order to get close to Reproducible Science? Carlo explained that this extra information in an ideal world is associated to the data (as metadata) in the data model of the research infrastructure/VRE (comparable to catalogue data in a library). At the moment it often needs to be added manually, but also sometimes is already generated automatically. He admitted that more effort still needs to be done to make this kind of information available in a good machine readable way.
Image Credits:
Featured Image: “Make it Happen – Carrying out Research and Analysing Data”, Background picture: Linking Open Data cloud diagram 2017, by Andrejs Abele, John P. McCrae, Paul Buitelaar, Anja Jentzsch and Richard Cyganiak. http://lod-cloud.net/ CC-BY-SA