

By the end of this section, you should be able to…
- Describe possible solutions to data heterogeneity
- Correctly use technical terminology around metadata, schema, standards, etc
- Understand the differences between different types of data standards
- Understand some of the reasons you would choose a particular data standard
The basic strategy proposed to provide some sort of solution to this problem is to ‘have standards’. By a ‘standard’, what is generally meant is a common means of representing and sharing data that would allow them to be comparable. The imposition of standards is generally enthusiastically supported once the data heterogeneity problem is realised (for more on ‘Standards’, visit the ‘Standards’ page in our ‘Introduction to Research Infrastructures’ module ).
Watch!
Watch our video for Mork and Tork, available in English, French, German, Greek and Italian!
That being said, what is meant by a ‘standard’ and the object to which it is meant to be applied is something that requires a closer analysis.
Metadata Schema and Metadata Standards
At the most general level, when thinking about standardizing information the objects of standardization are either:
- data values
- the data schema
Data schemas are the technical structuring mechanisms that allow the storage, presentation and querying of data in an information system. Thought of in simple terms, a data schema is anything between what one creates in generating a spreadsheet with discrete columns for recording unique pieces of information in relation to the generation of complex relational database structures in SQL in order to track multiple information streams and their relations.
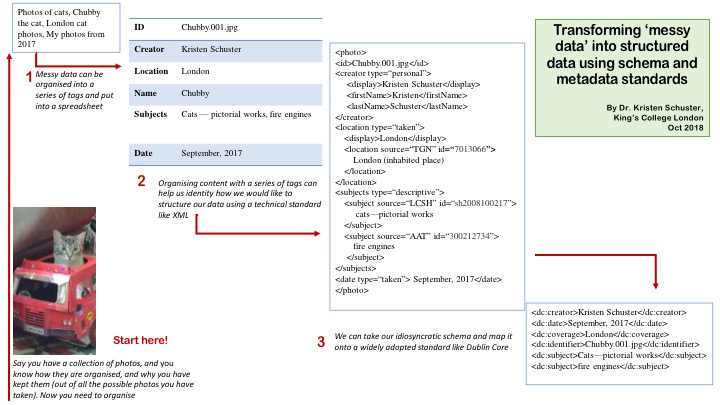
Transforming ‘messy’ data into structure data using schema and metadata standards
Each schema provides a means for expressing a certain range of information. But it does so at the cost of limiting the range of possible ways to describe a certain subject to the factors chosen for expression in that schema. That is to say, if you want to express data in a structured format, you are necessarily simplifying the data you can gather from the real world to just those factors you have chosen to codify in your schema. Picking and setting up some schema is NOT picking and setting up some other configuration of the information space. Data values are the individual points of information that can be entered into, presented from or queried over in a data schema by a user.
Different methodologies can be applied to data schemas and data values in order to achieve standardization. Relative to data values, we can speak of:
- Implementation of standardized vocabularies or thesauri and reference resources [E.g.: AAT, TGN, Geonames, ULAN, VIAF, DBPedia]
With regards to standardization and data schemas, we can mention three common strategies for bringing about standardization:
- Implementation of a minimal metadata standard
- Implementation of a maximal metadata standard
- Implementation of a formal ontology standard
It is with regards to the problem of standardizing data at the schema level that formal ontology plays an important role and offers a different approach than other methodologies. To see this contrast, we should consider, first, the approaches of implementing minimal or maximal metadata standards.
The idea of a minimal (basic) metadata standard is to approach the diversity that can be found across a series of datasets and look for generically applicable and usable high level descriptors that can be commonly adopted by all users. The minimal metadata standard is a reduced data description based on these categories. Examples of such a standard include efforts to apply Dublin Core and the Europeana Data Model. While well intentioned, the application of minimal metadata profiles for large-scale data integration can often be an insufficient means of creating meaningful and useful information integration. By having such high level data descriptors, the granularity of information and data detail details is lost. Generalist queries are enabled but more specific queries to sort down to the information that one is particularly interested in is not facilitated. Minimal metadata standards are useful up to a point, but they can begin to form a sort of Procrustean bed into which data much be forced, altering and perhaps also separating it from its semantic context along the way and rendering it insufficient for more complex research or retrieval purposes.
Below is an example of metadata for a book using Dublin Core elements
Title: The linguistics atlas of England
Creator: University of Leeds
Subject: Linguistics
Description: A book of maps showing phonetic, lexical, morphological and syntactic variations in dialects around England using data collected from the Survey of English Dialects.
Publisher: Humanities Press
Contributor: Orton, Harold
Contributor: Sanderson, Stewart
Contributor: Widdowson, John
Date: 1978
Identifier: 0-85664-294-0
And how that looks in XML (using https://nsteffel.github.io/dublin_core_generator/generator_nq.html#contributor):
Example of metadata in Dublin Core (XML).

On the other hand, maximal (advanced) metadata standards attempt to come up with a comprehensive set of descriptors that are suitable to a particular domain, expressing in a complete and accurate way the present state of knowledge and means of description for that field of research. It is typical to limit such standards to a domain so that the range of information to be described is not impossibly large. Because of the maximal aim of representation that such a standard tries to achieve, its use in ‘universal’ applications that are not bound to a particular disciplinary field is limited. In other words, it cannot be all things to all applications. The range of knowledge to be represented would simply be too much. Such standards are a heavy investment to build and make often misguided assumptions about the likelihood of a conversion of mass user-groups to this mode of expression. Furthermore, the sheer size of such standards can make them difficult to use or implement. Finally, given the evolutionary nature of scholarly and scientific knowledge, such schemas are subject to a heavy burden of revision to keep up with new research and methods that create new descriptors and require new data structures.
Below you will see a webpage from the Library of Congress, which is displaying the metadata of an item from one from of their collections.
Task 1 – Count how many metadata fields are presented for this item. How many more fields are there compared with the basic metadata field?
You can find the full XML for this record here: http://memory.loc.gov/diglib/ihas/loc.afc.afc9999005.1153/mods.xml, but we have provided a screengrab to as a demonstration:
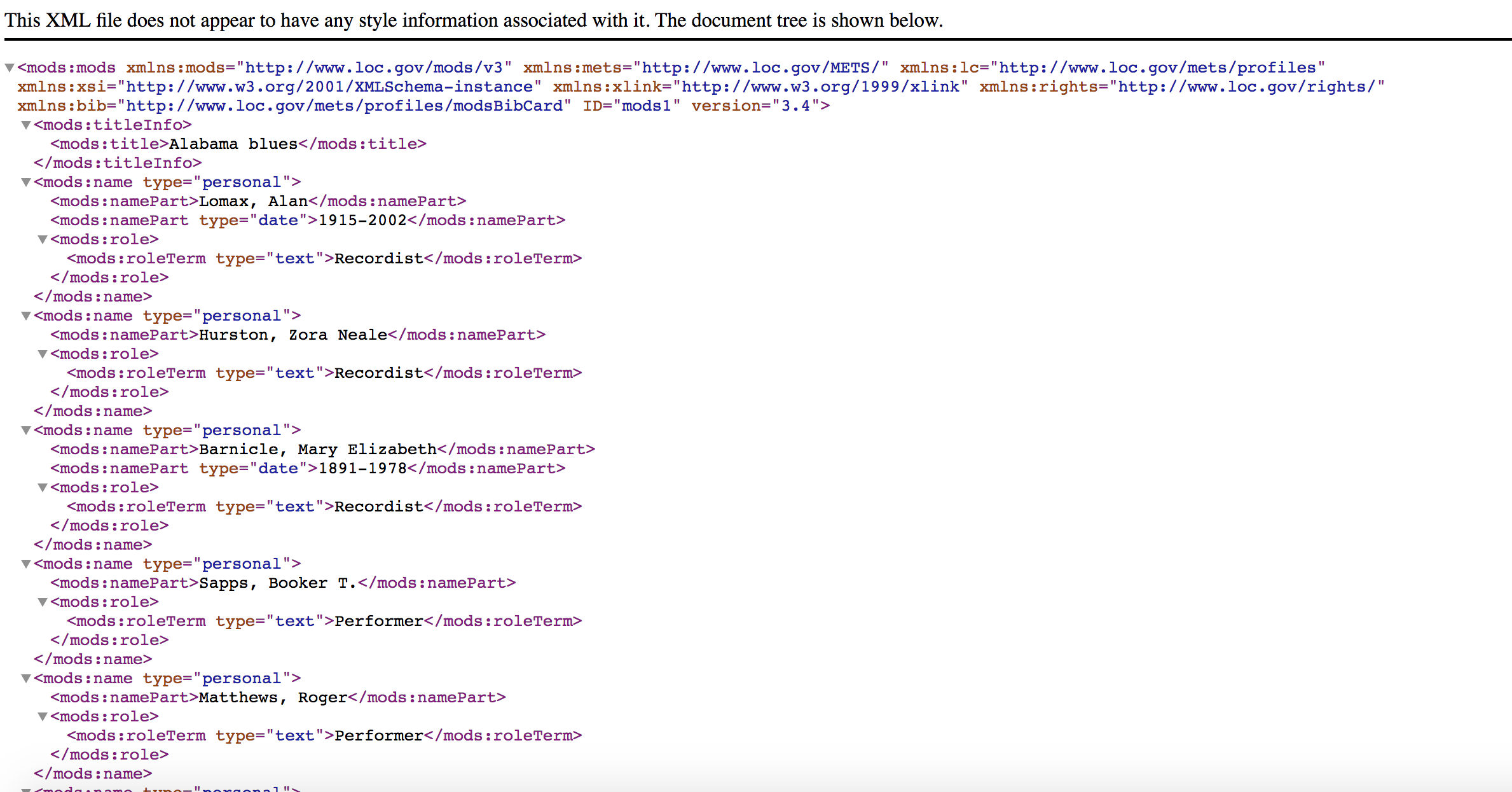
An screengrab of the XML attached to the MODS metadata for the Alabama Blues record in the Library of Congress
In fact, both minimal and maximal metadata standards provide useful solutions for data integration in appropriate application contexts. Minimal metadata strategies can provide a very light integration of resources at the most general level. This can provide a first step to tighter integrations. Maximal metadata standards are useful to implement in closed scenarios wherein you have control over the various actors participating in a project and can achieve a wide and enforceable concensus on a particular mode of expression [ie where the potential users of the schema belong to a unified group that shares need to implement a single mode of expression for their data, such as a research group or institution]. Beyond this, however, they reach their technical limits for large scale data integration and another solution is needed: a formal ontology.
Thesauri and Authority Files – why do we need them?
Before turning to formal ontologies, however, it is useful to quickly point to the role of thesauri and authority files in the process of standardization at the data level. Regardless of the standardization method chosen for the schema level, data integration is only fully achieved when harmonization is carried out also on the data value level. Enabling such standardization are thesauri and authority files. These are curated lists of either controlled terminologies or controlled references.
Controlled thesauri are generally curated by a specific community and provide a list of terms and their (un)official spellings for those concepts that are recognized and used for describing some aspect of reality. A classic example is the Getty Art and Architecture Thesaurus.
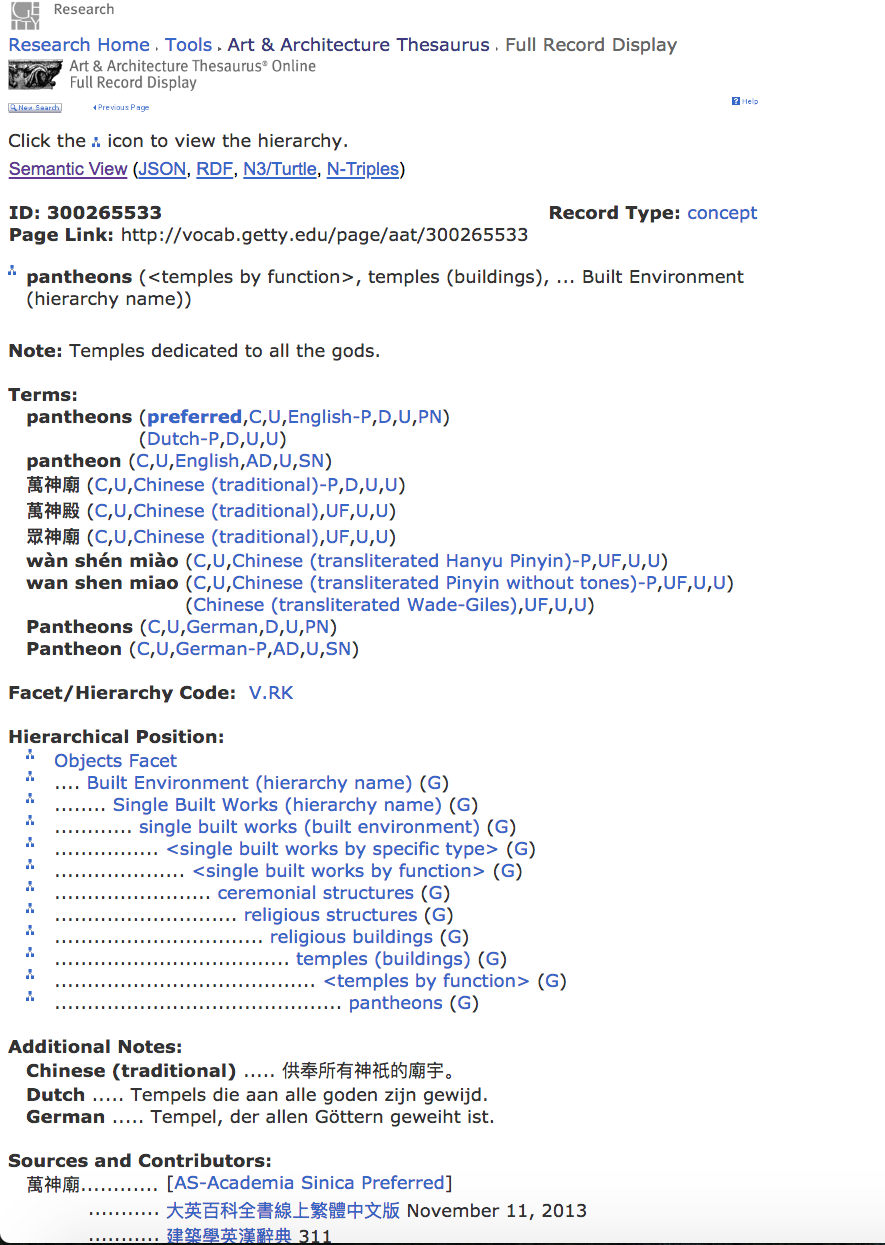
Example of Getty AAT Thesaurus
In this example, you can see how the Pantheon in Rome might be categorised, and where it might fit in a hierarchy of terminology. In this case, note how far down the hierarchy ‘pantheons’ appears, and all the different sub-categories applied to it within the hierarchy.
a) Find the ‘Note’ on this screengrab
b) go to the Getty Arts and Architecture Thesaurus (http://www.getty.edu/research/tools/vocabularies/aat/) and search for ‘Town Hall’. Compare the hierarchy for this with that of the Pantheon in this picture. What do you notice is different? At what point in the hierarchy do the two buildings diverge?
c) what is the ‘preferred’ term for ‘Town Hall’ in the Getty AAT?
An authority file, on the other hand, is a curated list of real world references in which the interest is not in precisely defined intellectual categories but in clearly identified individuals to be referenced in the world. This means that when you are looking up a particular person, but aren’t sure of the spelling, or how that person is referenced elsewhere in the world, this resource can give you the correct format for a name.
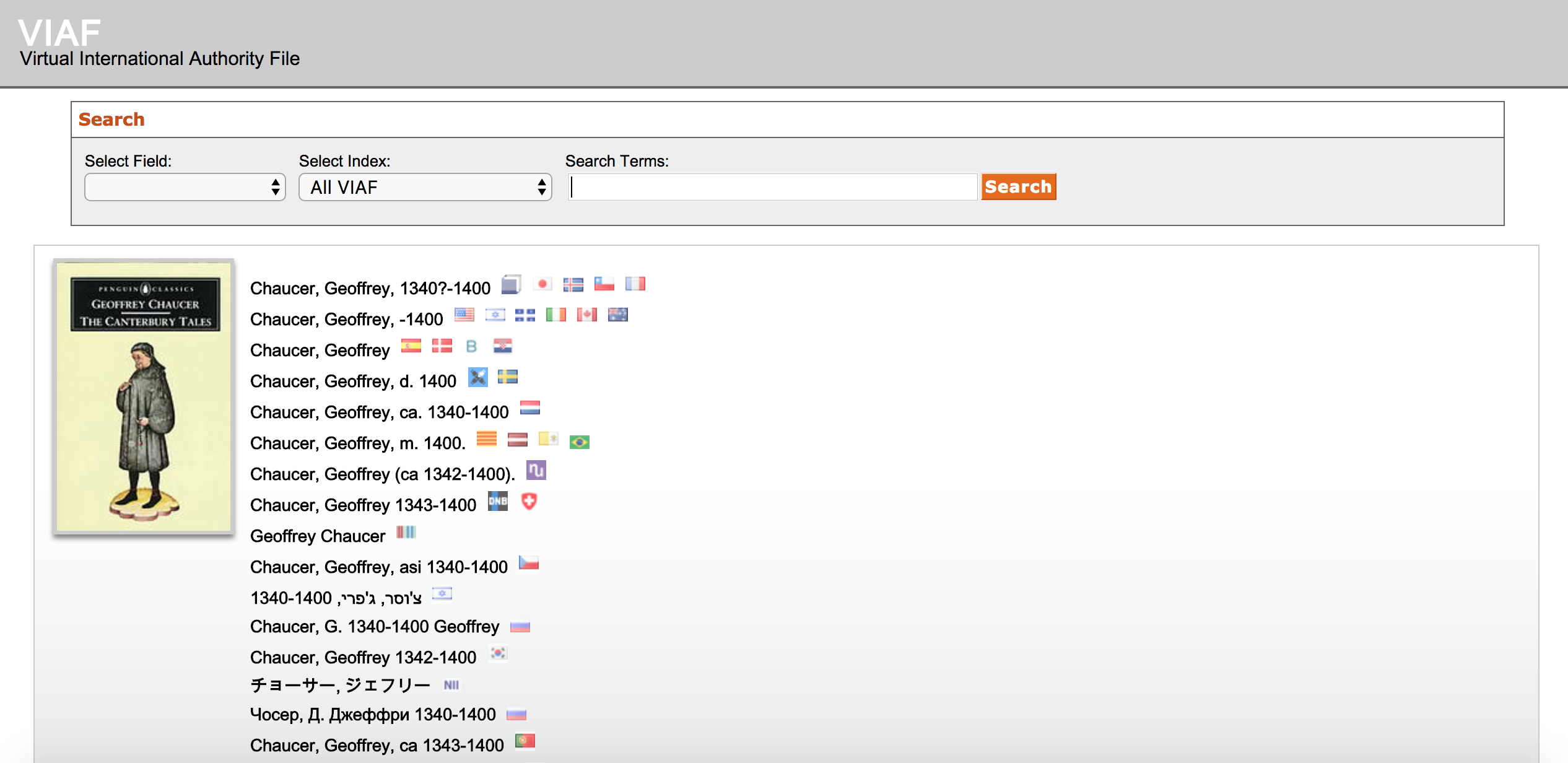
An example of a record in VIAF
Classic examples of these are provided by Getty with the Getty Thesaurus of Geographic Names and the Cultural Objects Name Authority and by OCLC with the Virtual International Authority File for persons.
When planning for and implementing data integration, it is important to consider which thesauri and authority files best apply to your domain of research, regardless the strategy chosen for controlling the schema.
- “A Framework of Guidance for Building Good Digital Collections | NISO Website.” n.d. Accessed January 23, 2018. http://www.niso.org/publications/framework-guidance-building-good-digital-collections.
- “Best Practices for Digital Humanities Projects | Center for Digital Research in the Humanities | University of Nebraska–Lincoln.” n.d. Accessed January 23, 2018. https://cdrh.unl.edu/articles/best_practices.
- “Dublin Core Metadata Initiative.” n.d. Accessed January 23, 2018. http://dublincore.org/.
- “EAD: Encoded Archival Description (EAD Official Site, Library of Congress).” n.d. Accessed January 23, 2018. http://www.loc.gov/ead/.
- “Europeana Data Model Documentation.” n.d. Europeana. Accessed January 23, 2018. /resources/standardization-tools/edm-documentation.
- “Getty Vocabularies (Getty Research Institute).” n.d. Accessed January 23, 2018. http://www.getty.edu/research/tools/vocabularies/.
- Gill, Tony, and Paul Miller. 2002. “Re-Inventing the Wheel? Standards, Interoperability and Digital Cultural Content.” D-Lib Magazine 8 (1). https://doi.org/10.1045/january2002-gill.
- “Metadata Encoding and Transmission Standard (METS) Official Web Site | Library of Congress.” n.d. Accessed January 23, 2018. http://www.loc.gov/standards/mets/.
- “Metadata Object Description Schema: MODS (Library of Congress Standards).” n.d. Webpage. Accessed January 23, 2018. http://www.loc.gov/standards/mods/.
- “TEI: Text Encoding Initiative.” n.d. Accessed January 23, 2018. http://www.tei-c.org/index.xml.
- “VIAF.” n.d. Accessed January 23, 2018. https://viaf.org/.