

By the end of this section, you will be able to…
- Understand the peculiarities of social media corpora as a research dataset
- Understand the most frequent encoding standards for social media corpora
- Understand the most important metadata in social media corpora
- Understand the most common annotation layers in social media corpora
Social media data as a research dataset
Social media corpora have some important characteristics that researchers need to take into account throughout their work. Their most distinguishing characteristic is that social media posts are produced in uncontrolled and unregulated settings by people from different backgrounds (e.g. undergraduate students, politicians), with different motivations (e.g. chatting with friends about a concert, campaigning) and on different technical devices (e.g. smartphones, laptop computers). Many of the posts are published in a highly interactive, instantaneous setting (similar to face-to-face spoken discussions) and include non-verbal elements, such as images or videos, and are rich in new media features, such as emoji, mentions, hyperlinks and hashtags. In addition to post content, metadata about the post (e.g. time of posting, number of favourites or number of retweets) and metadata about the user (e.g. user profile, friends) can be often harvested as well. For this reason, social media corpora are also rich in invaluable (sociodemographic) metadata. To enable data-driven science, social media data should be collected, processed and distributed in accordance with the legal and ethical standards, encoded according to international standards and recommendations, and accompanied with rich and correct annotations and metadata.
Legal and ethical issues
When dealing with social media data, especially if they are non-public, data acquisition and dissemination is quite complex. Due to legal concerns, ethical issues and technical demands related to data retrieval and the linking of mixed resources (e.g. linking the content of the posts with the sociodemographic metadata), researchers are increasingly choosing between two options. For smaller collections, they first seek explicit user consent and then share the entire collection, which includes the data, metadata and annotations. This approach has been followed in the DiDi project and the What’s up Switzerland project. In the case of larger collections, for which obtaining user consent from every individual is not feasible, only post IDs are shared, based on which other researchers can obtain the texts and their metadata on their own, provided that the content has not been removed. While this model brings a lot of benefits in terms of controlled and comprehensive data collection on a large scale, it also makes it harder to share the textual annotations along with the text (e.g. lemmas and standardized forms of non-standardly spelled words, as they give a close approximation of the original text). The JANES project, which has followed the latter approach, provides a specialized encoder program that keeps only the annotation differences against the original text, and a decoder that, upon retrieving the original text given its ID, reconstitutes the annotations.
Encoding of social media data
Source files: Social media content obtained through APIs offered by content providers typically come in a light-weight JSON format, which is readable by humans and easy to process by computers. Collaborative content, such as Wikipedia, is available in XML dumps for which parsers already exist. User-generated content harvested from websites in HTML, on the other hand, requires dedicated text and metadata extraction scripts.






Encoding standards:
No encoding standard has been widely accepted for social media corpora. But there is a special interest group (SIG) on Computer-Mediated Communication in the Text Encoding Initiative (TEI), which is working on extending the TEI framework with additions dedicated to the representation of the structural and linguistic peculiarities of CMC genres. The latest version (Beißwenger et al. 2016) of the proposed schema extends the TEI-P5 guidelines to reflect the following specific properties of the social media genre: new elements (e.g. for a written contribution to a discussion thread), new attributes (e.g. @auto for automatically generated messages) and adaptations of content models (e.g. may occur without the rigid positional constraints as is typical for more traditional texts). Many social media corpora are therefore still encoded in bespoke formats.

Metadata
Social media data are rich in extralinguistic markup at the post level (e.g. posting time, number of retweets, number of likes) as well as at the user level (e.g. username, location, bio). Some of the metadata are readily available and can be downloaded along with the actual data while other metadata can be inferred from the content of the posts (e.g. user’s gender, post sentiment, post language) or from external knowledge sources (e.g. politician’s party affiliation obtained from official parliamentary databases or from wikipedia, socioeconomic information on the user’s region taken from the national statistical office). The available metadata are invaluable as variables in analyses but can also be used for further filtering of the corpus. Inferring the missing (socio)demographic information about a user, such as gender, age, location, political orientation or even different personality traits, based on the content of their posts and posting dynamics, is called author profiling and is currently a very popular research problem in data mining.
On-line communities are formed based on the users’ common interests and goals. The social network structure is reflected through the follower information, mentions and replies, and is often used in tasks like sentiment analysis or cyberbullying detection.
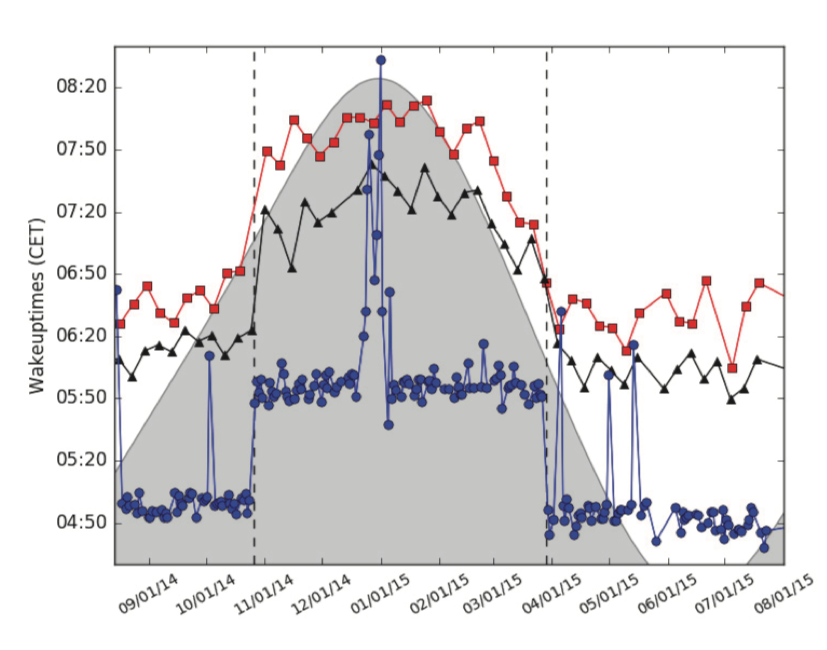 Figure 8. Analysis of the onset of tweeting activity during the week (blue), on Saturday (black) and Sunday (red) of German Twitter users. Vertical dashed lines marks the transition from/to the Daylight Saving Time. Dawn is shown in the grey-white transition (click for larger image). |
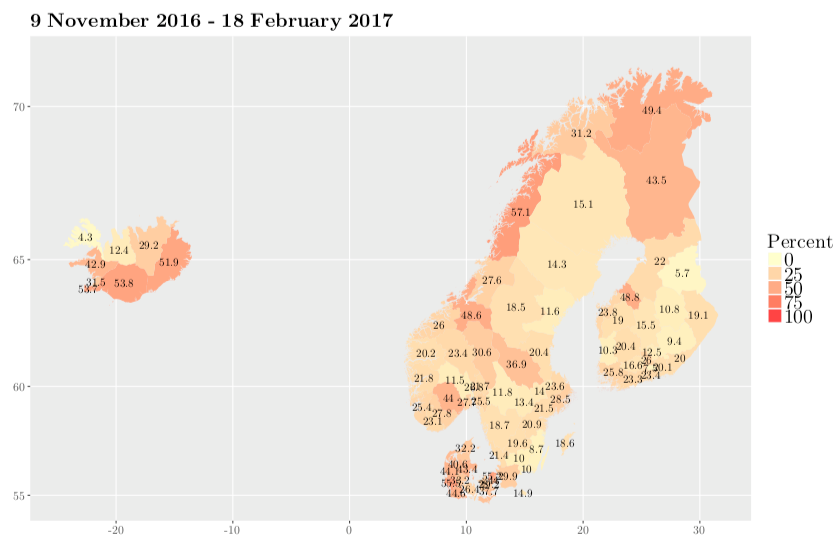 Figure 9. Percentage of gendered tweets according to users’ names posted in English in the Nordic countries (Click for larger image). |
Linguistic annotations and text enrichment

One of the most distinguishing characteristics of social media is the language used in the posts, which frequently considerably deviates from the norm (e.g. missing diacritics, phoneticized spelling, slang words), making even basic linguistic annotations, such as tokenization (marking word boundaries), sentence segmentation (marking sentence boundaries), morphosyntactic tagging (adding information on the part of speech and other morphosyntactic characteristics of each word in the corpus) and lemmatization (providing the base, dictionary forms of the inflected words) very difficult. Social media specific annotation tools therefore need to be trained on hand-annotated social media texts (so called domain adaptation), or the non-standard words need to be standardized before regular annotation tools are applied. This annotation layer, which is also used in historical and spoken corpora, is called normalisation (e.g. tmrw, 2morrow -> tomorrow) and is useful not only for the text processing tools but also for humans, so that they can easily search through all the spelling variants in the corpus.
Similar to parliamentary corpora, social media corpora are also very frequently enriched with the annotations of named entities (names of persons, organizations and places), sentiment (information on whether a speech conveys a positive, negative or neutral attitude about the subject matter) and topics.

Figure 11. Illustration of named entity recognition in social media corpora.
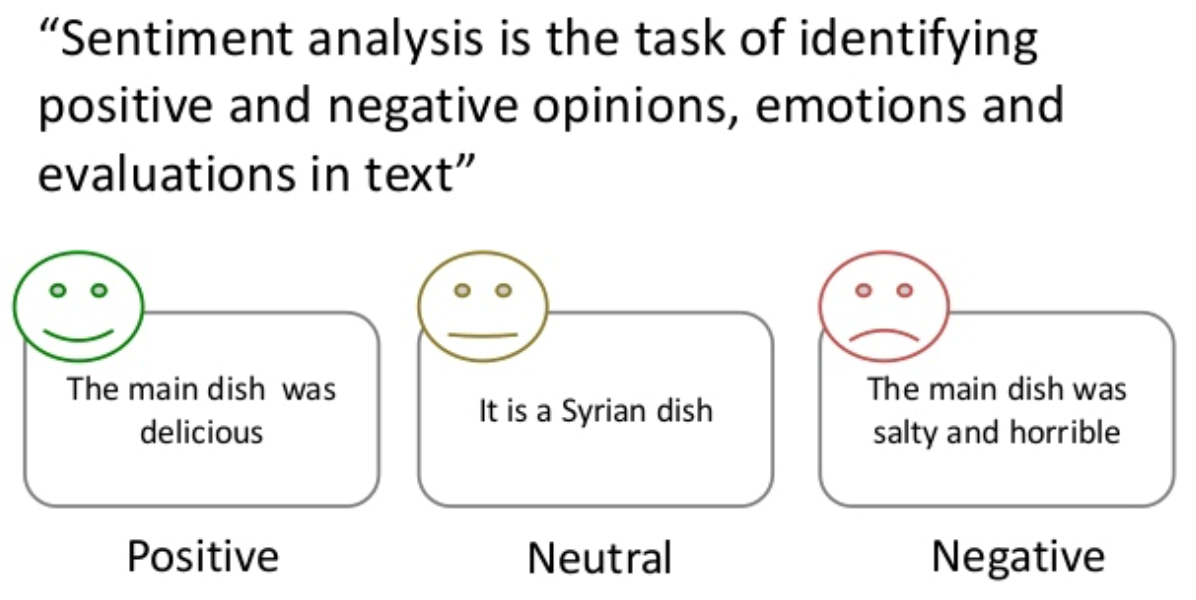
Figure 12. Illustration of sentiment analysis in social media corpora.
Image Credits:
- Figure 1 is taken from https://gist.github.com/hrp/900964.
- Figure 2 is taken from https://twitter.com/PostGradProblem.
- Figure 3&4 are taken from https://dumps.wikimedia.org with https://github.com/nljubesi/wikitalk-extractor.
- Figure 5&6 are taken from http://www.shakesville.com/2018/11/mo-salah-just-got-jammed.html.
- Figure 7 is taken from http://www.chatkorpus.tu-dortmund.de/tei/tei_CMC_CHATCORPUS2CLARIN_SHORT.html#TEI.post.
- Figure 8 is taken from Scheffler et al. (2016). In: Proceedings of the Tenth International AAAI Conference on Web and Social Media (ICWSM 2016) [link to PDF], Figure 4 page 677.
- Figure 9 is taken from Coats et al. (2017). In: Investigating Computer-Mediated Communication: Corpus-based Approaches to Language in the Digital World [link to PDF], Figure 1 page 109.
- Figure 10 is taken from Fišer, Ljubešić, & Erjavec (2018). Lang Resources & Evaluation. https://doi.org/10.1007/s10579-018-9425-z.
- Figure 11 is taken from http://blog.digitalglobe.com/developers/named-entity-recognition-for-twitter/.
- Figure 12 is taken from https://www.slideshare.net/Staano/evaluation-datasets-for-twitter-sentiment-analysis-a-survey-and-a-new-dataset-the-stsgold.
- Beißwenger, Michael, Thierry Chanier, Tomaž Erjavec, Darja Fišer, Axel Herold, Nikola Ljubešic, Harald Lüngen et al. “Closing a Gap in the Language Resources Landscape: Groundwork and Best Practices from Projects on Computer-mediated Communication in four European Countries.” In Selected papers from the CLARIN Annual Conference 2016, Aix-en-Provence, 26–28 October 2016, CLARIN Common Language Resources and Technology Infrastructure, no. 136, pp. 1-18. Linköping University Electronic Press, 2017. Link to PDF: http://www.ep.liu.se/ecp/136/001/ecp17136001.pdf
Videos
- CLARIN-PLUS Workshop “Creation and Use of Social Media Resources”, Kaunas 2017: http://videolectures.net/clarinplusworkshop2017_kaunas/