

As explained above, the digitisation of newspapers creates new objects that offer enhanced searchability, but particular care is needed when using them. A few questions can help estimate how many articles may have been missed because of OCR mistakes.
Is the collection I’m browsing prone to particular weaknesses because of its font?
Digitising historical newspapers involves deciphering a variety of font formats. German-speaking newspapers used to be published in Gothic font (Fraktur), a calligraphic-style font. Standard OCR is prone to more misidentification with this font than with Roman typefaces. Alongside dedicated models for the recognition of Gothic fonts, recently, software developed for handwriting recognition (HWR), also known as handwritten text recognition (HTR), has delivered very promising results.
Users should bear in mind, however, that OCR for Fraktur is still generally speaking weaker than for Roman font collections and should diversify their queries to compensate for this weakness.
Newspapers produced with poor paper quality, for example during wartime or for clandestine purposes, will tend to produce a lower quality scanned version. For instance, pages may be torn, or the paper may be so thin that text from the other side shines through and creates noise for the OCR.
Is the query term very common or very rare? Is it long or short?
The quality of OCR depends on the identification of characters and then post-correction. The recognised characters are checked against lexicons to verify the recognition of words listed in common dictionaries. This processing creates new biases, as Guillaume Chiron (Chiron et alii., 2017) explains. Basing his research on actual queries via the Europeana and French National Library (BnF) interfaces, he observed that many keywords used for queries are often unique and very specific. The more specific they are, the less chance they will be found in standard dictionaries and hence be corrected in the post-OCR correction process. Generally, if a word has more letters, the chances of one letter being misidentified are higher. But this problem can be circumvented with search options offering more flexible query formulation (known as “fuzzy search”) that can be made available for researchers by the search engine.
Can we identify some OCR mistakes in the retrieved articles to feed new keyword lists with these spellings?
This is the commonly used “snowball” strategy: after the first query of a word, you may come across a different OCR version of the queried word and try it out as a separate query.
To what extent have the newspapers been segmented?
The OCR processing of newspapers raises a few particular issues, mainly because some periods are characterised by poor paper quality, for instance in wartime, and some fonts used in headlines for articles or on the front page are difficult to read. Another big challenge is segmentation: searching for two keywords in a single article or an entire issue of a newspaper may give very different results, especially when searching for terms that are less frequently associated with each other.
For instance, searching for Argentinian tango and Finnish tango will bring very different results when using collections that allow searches within one article or per issues (see ‘Ranke2’ in the “Further Learning” section at the bottom of this page).
Beyond big data: keeping things in proportion
Are there some surprising chronological holes in the list of results? This could be linked to a poor paper quality that leads to poor digitisation output and consequently, poor OCR output.
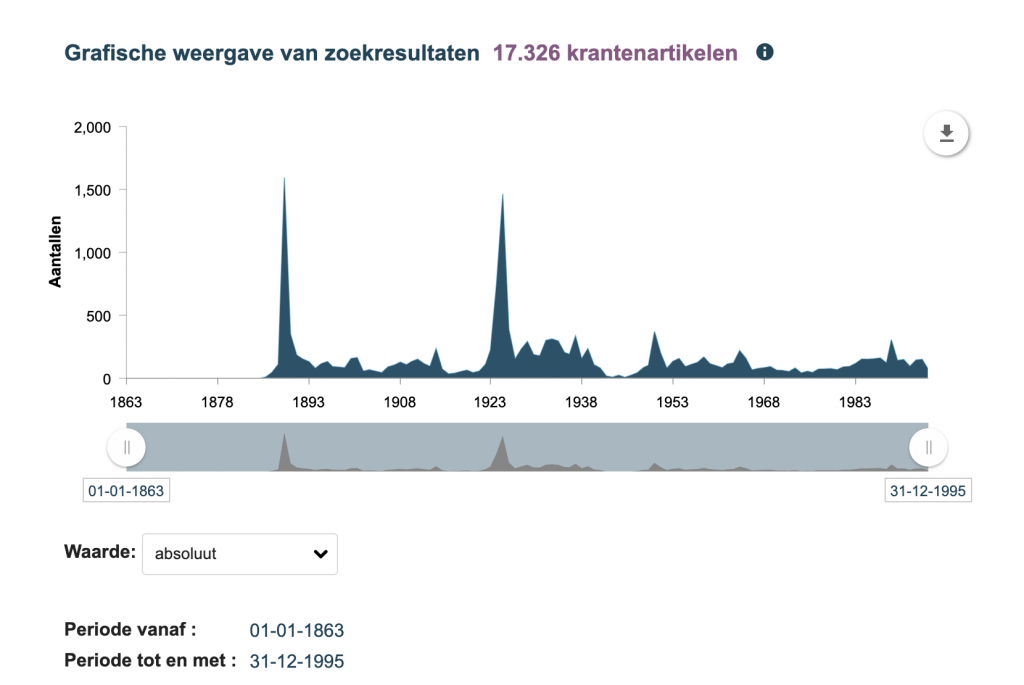
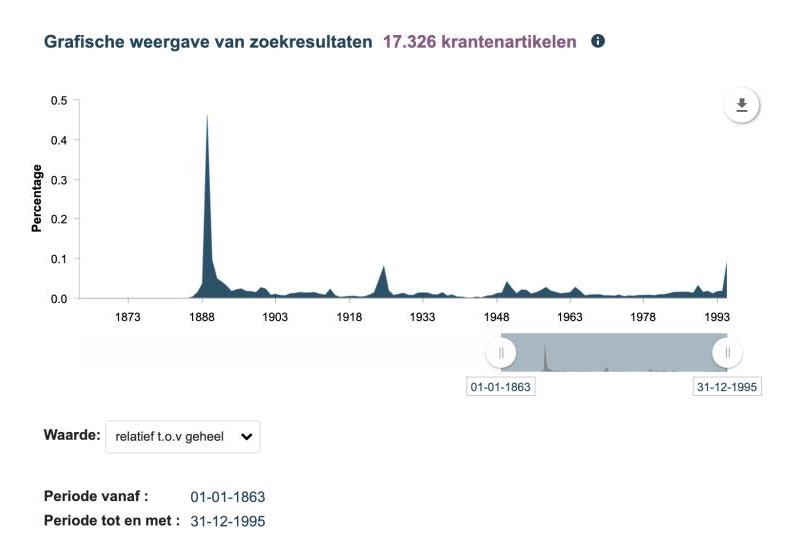
Some interfaces offer the option of frequency visualisation that can provide an overview of the distribution of results over time. The interface of the Royal Dutch Library, Delpher, has such a feature and is also noticeable because of the option to change absolute frequencies to relative frequencies. Choosing relative values displays the proportion of results compared to the entire digitised collection. See below the example of hits for “Titanic”, where the difference between relative and absolute is not too strong, indicating that a significant proportion of the newspapers that have been digitised covered the disaster in 1912. The query on “Eiffel Tower”, by contrast, shows that the proportion decreases when comparing the two peaks, even though the absolute values are more comparable.
URL
Delpher Timeline on Titanic
Delpher Timline on Eiffel Tower
Absolute Frequency
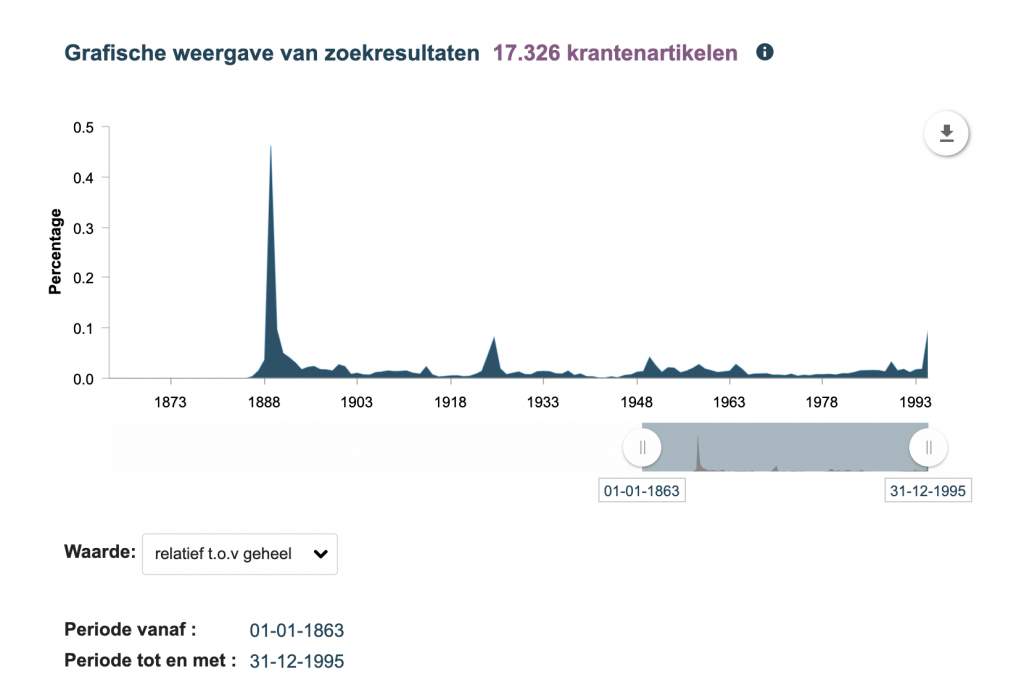
Relative Frequency
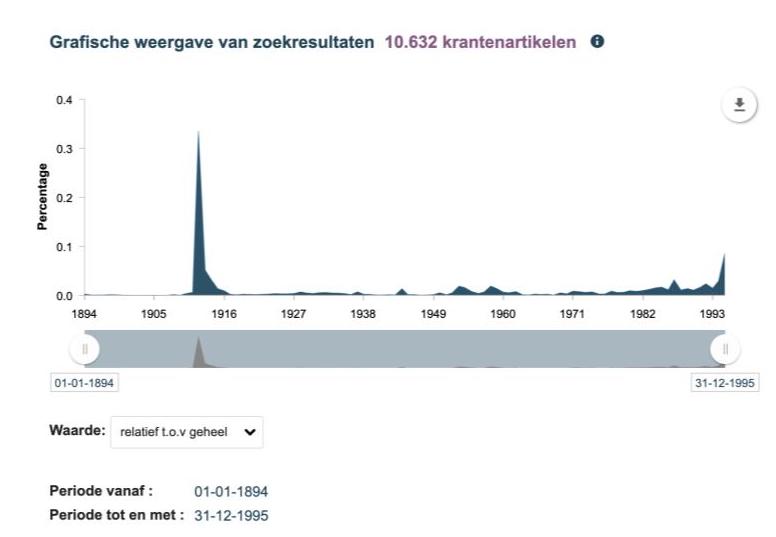
Click on an image to enlarge (when done, hit the ‘back’ button in your browser)
Be aware of the missing elements
There could be several reasons to explain the missing issues of a newspaper in a digital collection:
- the issue may not be available in the archives of the analogue collection
- the issue may have been damaged
- the digitisation may have produced unusable OCR
- the file may have been corrupted
From a user perspective, it is not always possible to estimate what is missing and for what reason. But it is important to be aware of this and to bear it in mind when browsing the collections, rather than just focusing on your queries.
An example of a damaged scanned page can be seen on the ANNO interface: http://anno.onb.ac.at/cgi-content/anno?datum=19120414&zoom=33

Digitisation of newspapers – in summary
- Optical Character Recognition (OCR) software makes newspapers searchable with keywords.
- The OCR quality varies significantly depending on the quality of the original source, the font used in the newspaper and the performance of the OCR software.
- It is difficult to estimate the impact of OCR mistakes on the search for each keyword, but some keywords are more prone to misidentification, particularly when the word is long or not available in dictionaries used by OCR software.
- As searched words may be repeated in one single article, OCR mistakes can be compensated through machine learning.
- The segmented layout of newspapers can also be digitised via OLR, which opens up the application of new search filters, limited to sections of newspapers such as advertisement, obituaries.
- Metadata standards such as METS/ALTO help to store the location of characters on the scanned image.
- A wider search within a collection using different keywords can help to get a better understanding of the context of the article, and what might be missing from the overall digitised resource.
- Ranke2 – Critical analysis of digital resources: https://ranke2.uni.lu/u/archival-digital-turn/