

By the end of this section, you should be able to…
- Understand how digitised newspaper interfaces are developed and how to make the most of them for scholarly research
- Understand how to diversify your queries and access sections of digitised newspapers via currently available interfaces.
Collections of digitised newspapers are part of a more general trend of providing online access to historical sources: there are increasing numbers of digitised cultural heritage collections, digital libraries and web archives. We have seen so far how the digitisation of newspapers functions in a general way; we will now explore how to access currently available collections in practice. The materiality of digitised newspapers is defined not only by the process of digitisation but also by the interfaces produced by the holders of digitised collections to provide access to these collections. Another crucial element over which holders generally have little influence (especially in the case of national libraries) is copyright, which can restrict access to digitised newspapers.
At the end of the digitisation and post-digitisation process, we find ourselves with several types of data, potentially stored in various databases, in different formats and in large quantities. Digitisation and processing create many entry points into newspaper collections: we can potentially search with keywords, filter by time period or language, search for given topics and identify people. But not all interfaces offer all these options. The interface is part of the general workflow of the researcher: queries are formulated based on previous research, and generally the researcher needs to take the results of the queries out of the interface to analyse them.
Interfaces are tools that are developed to organise communication between users and the databases produced by institutions in connection with their digitisation policies. The interface translates the queries and commands formulated by users and presents the answers produced by the databases. Interfaces are also an important place where information on the collections, their scope and the available commands is provided (Ehrmann 2019).
The interface is composed of several elements:
- the viewer, to read the newspapers
- search functions, to formulate queries to the databases
- exploration pages, to provide an overview and browse the collection in different ways rather than just with keyword queries
- contextual information, such as historical information about the newspaper or technical and institutional information on how the collection was produced
- some interfaces propose enhanced search options based on natural language processing, such as named entity recognition or topic modelling
Navigating institutional digitised newspaper collections
Reading the digitised newspapers
Digitised newspapers are not read in the same way as analogue ones. The scale is changed and, as is often mentioned, the context can be lost, as we can jump directly from a search list to a single article.
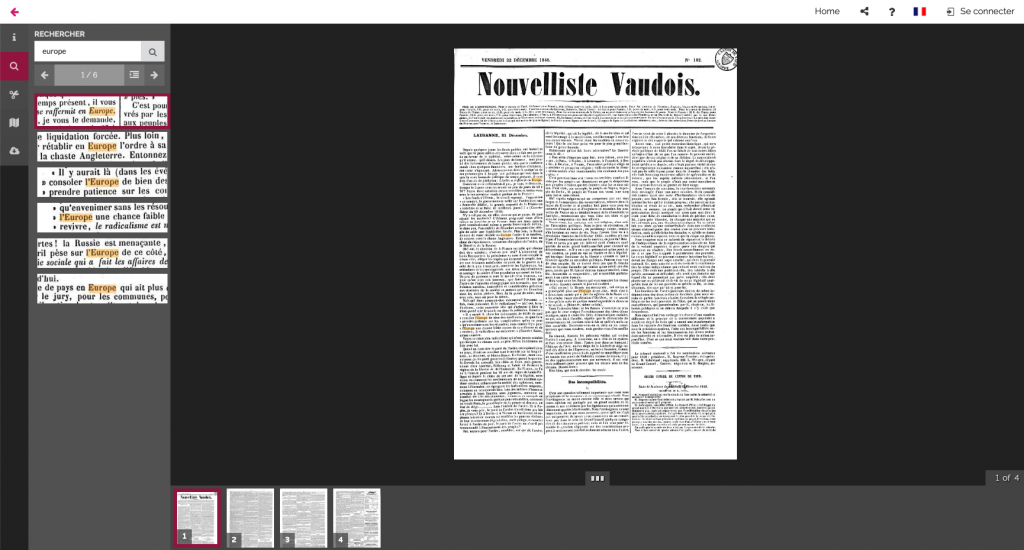
Some interfaces keep track of the context by providing a list of articles that are on the same page as the article being read. For instance, the California Digital Newspaper Collection lists the titles of articles on the page that is currently open:
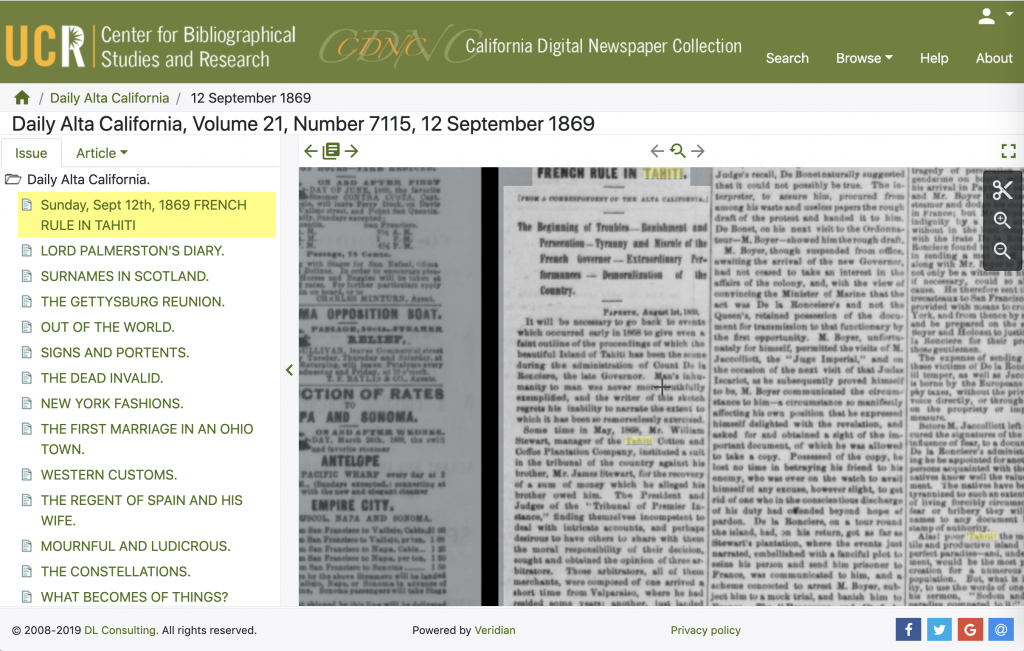
Other interfaces also display the segmentation that has been identified during the digitisation, for instance here in the viewer of the Luxembourg National Library:
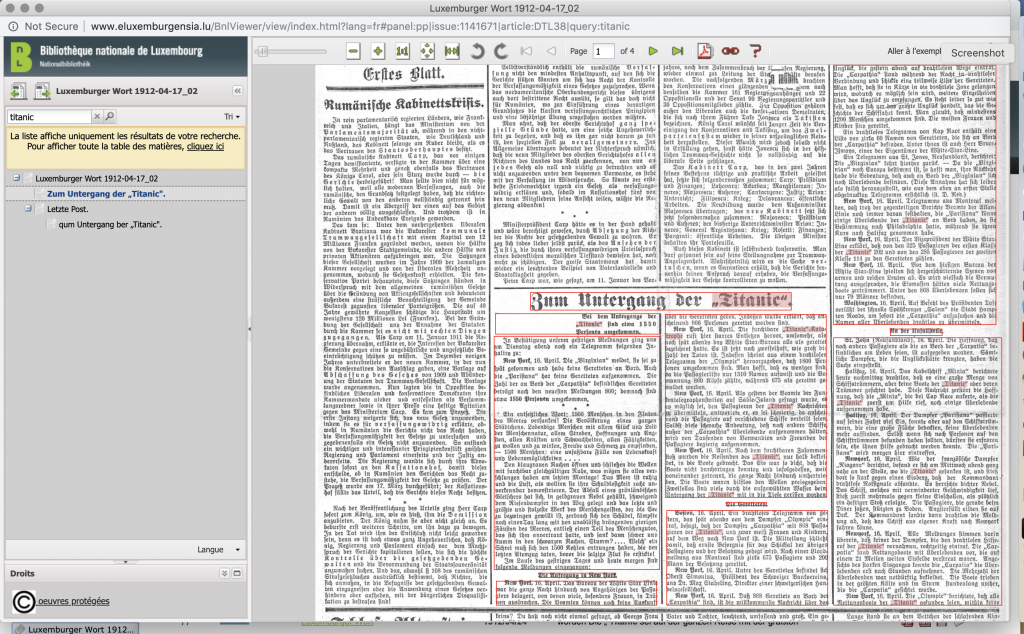
This same viewer displays the OCR that has been produced, alongside the scanned image:
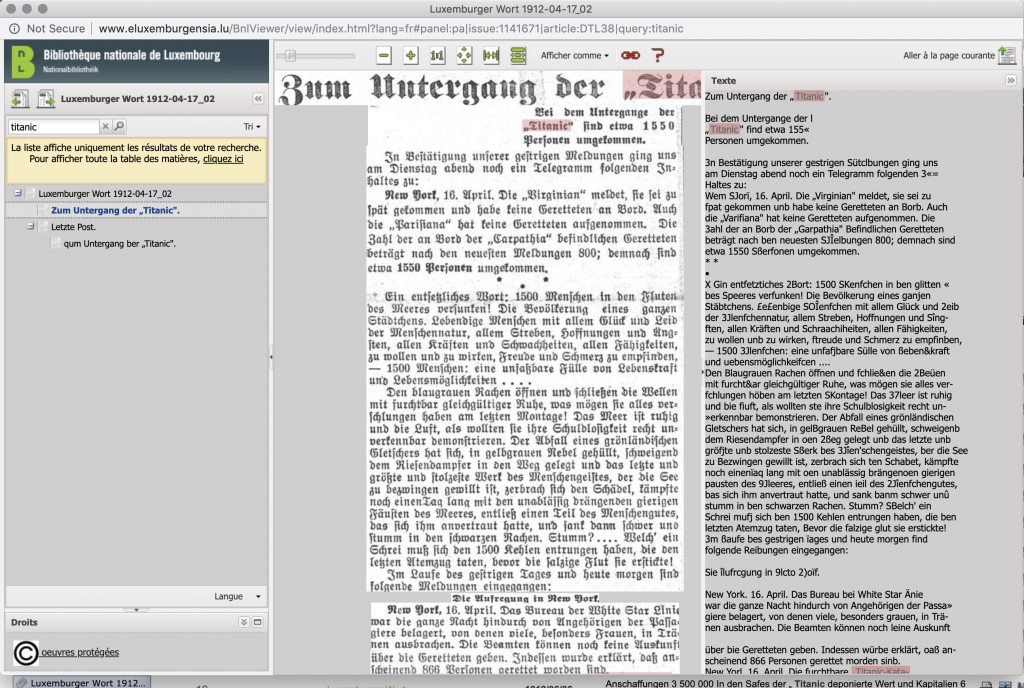
Most of interfaces offer the option to navigate from one page to the other in the newspaper issue that is being currently read. Some offer the option to navigate from one result to another:
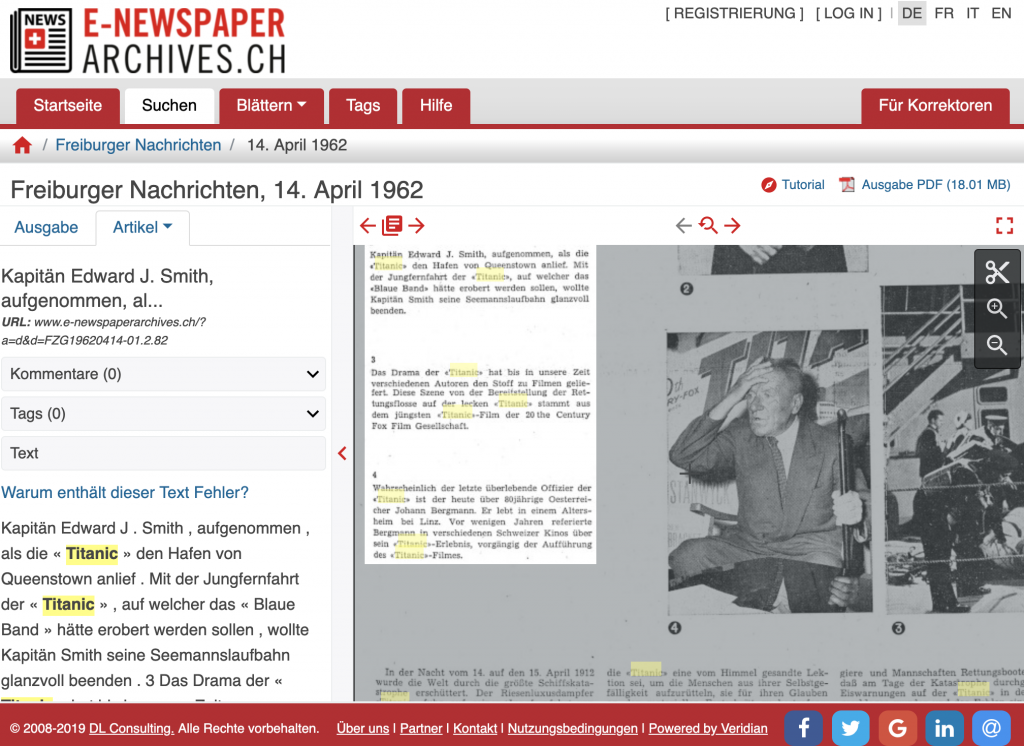
These examples show how some viewer options depend on the prior processing of the newspapers, for example article segmentation and identification of the article title. Others depend more on viewer functionalities: the display of OCR, navigation between results, etc. The viewer is relatively self-explanatory since it uses navigation options that are fairly familiar to us.
Searching the content of millions of pages
The main advantage of digitising newspapers is that it makes them searchable. This depends on the quality of the OCR, as we have seen, but also on various less obvious processing factors and on the design of the database.
Most interfaces offer keyword searches and the option of using metadata to restrict the search results.
When performing a large query, the Delpher interface flags up a warning:
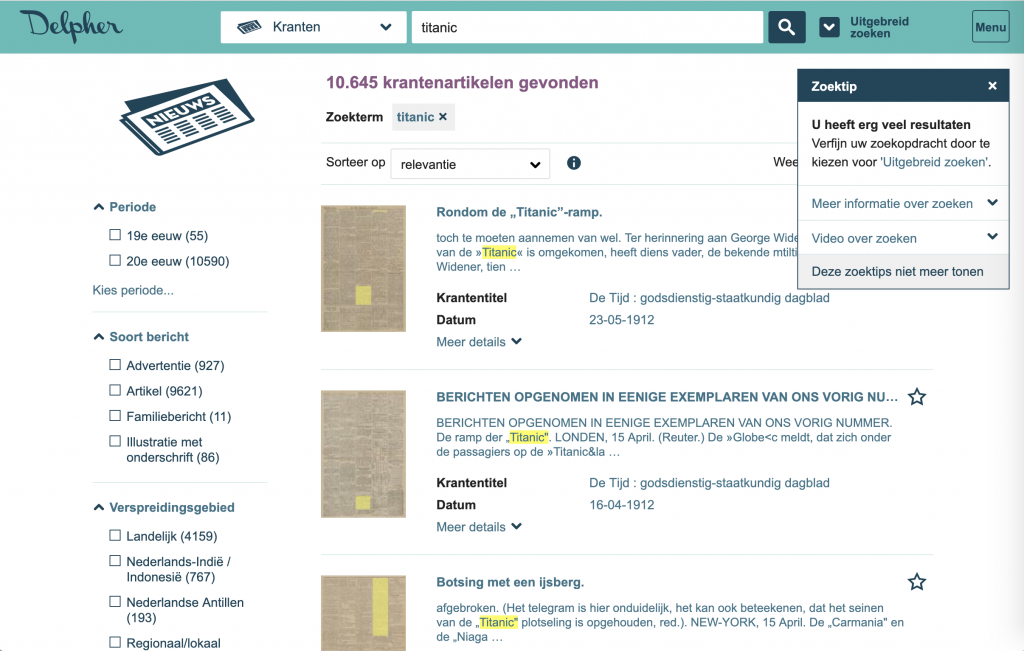
Most interfaces present the metadata that can be actioned as filters on the left pane of the interface. It is the content of these metadata that is highly variable. Most of the time we find the same filters as in a library catalogue, such as date, author and newspaper title.
Some other filters are used less frequently, such as ‘place of distribution’, or ‘article type’. In the case of Delpher, it enables the user to limit the search to newspapers published in the Netherlands or in the Dutch colonies. Users can also limit the search to certain broad types of articles: articles containing birth or wedding announcements; an option often of use to historians or genealogists. Users can also search for articles with an image. All of these filters depend on the decisions made during the processing of the collections.
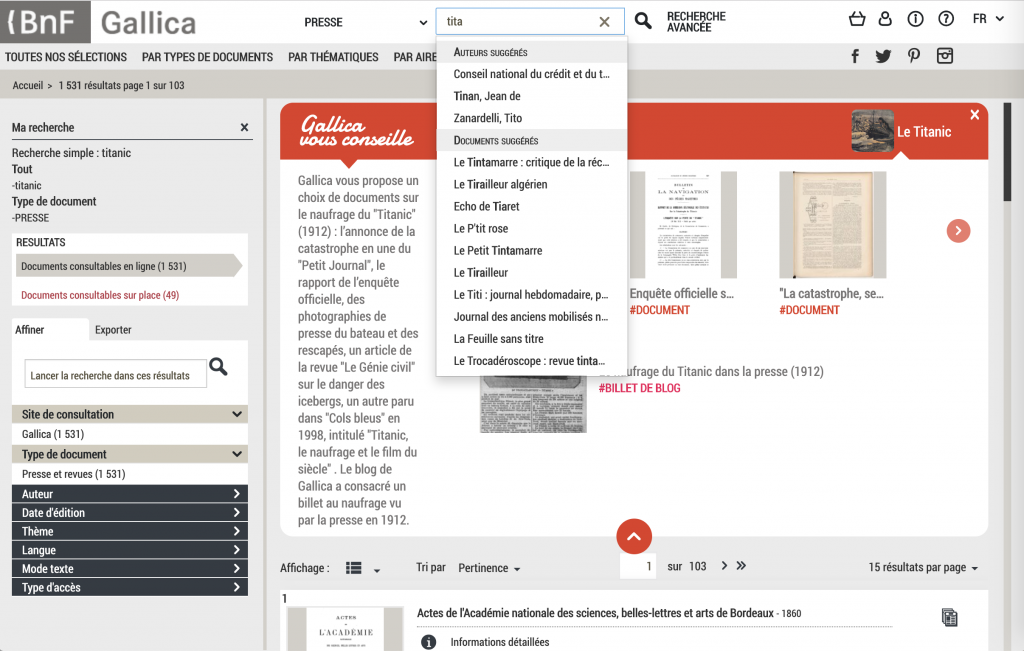
To give some more guidance on keyword searches, some interfaces offer an autocomplete option, based on the content of the collection. For instance, Gallica offers suggestions based on document titles and authors.
Navigating the collections of digitised newspapers
Bearing in mind all the limits of OCR and digitisation, users should not hesitate to browse newspaper collections more generally, to gain a broader understanding of what may or may not be available. Some interfaces offer several ways to discover what they contain.
- Newspapers by alphabetical order
- Available titles by country
- Most recently added titles
- Option of browsing the front pages for a given day
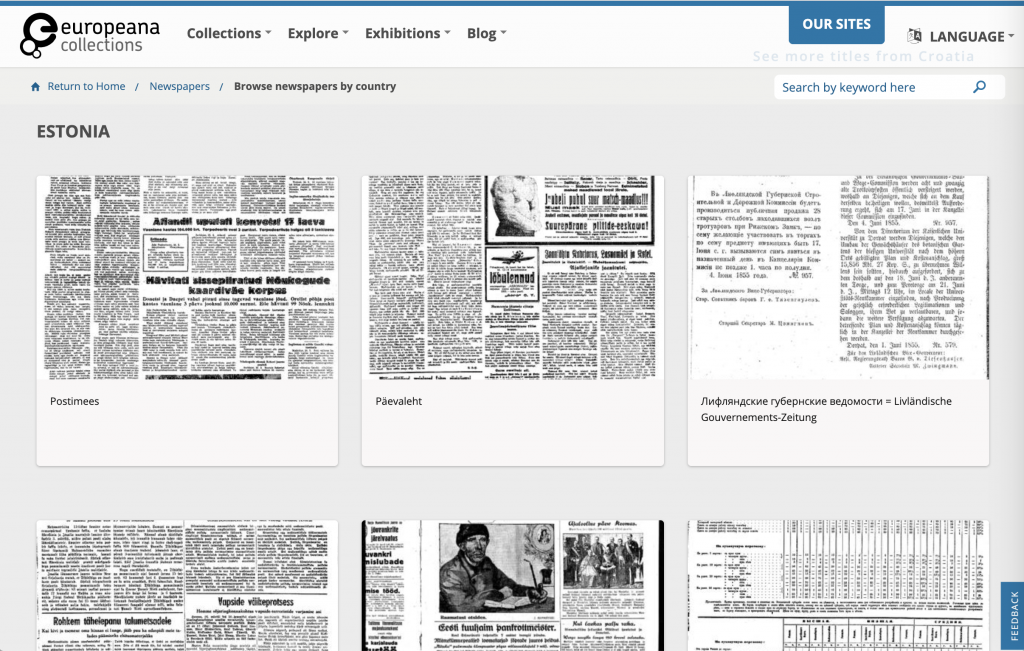
The Europeana newspaper interface offers different overviews of its collections:
Some interfaces inform users of the most recently added titles, such as ANNO:

Some interfaces also offer the option of browsing the front pages for a given day.

The GIF below shows the process of selecting newspapers from a given day:
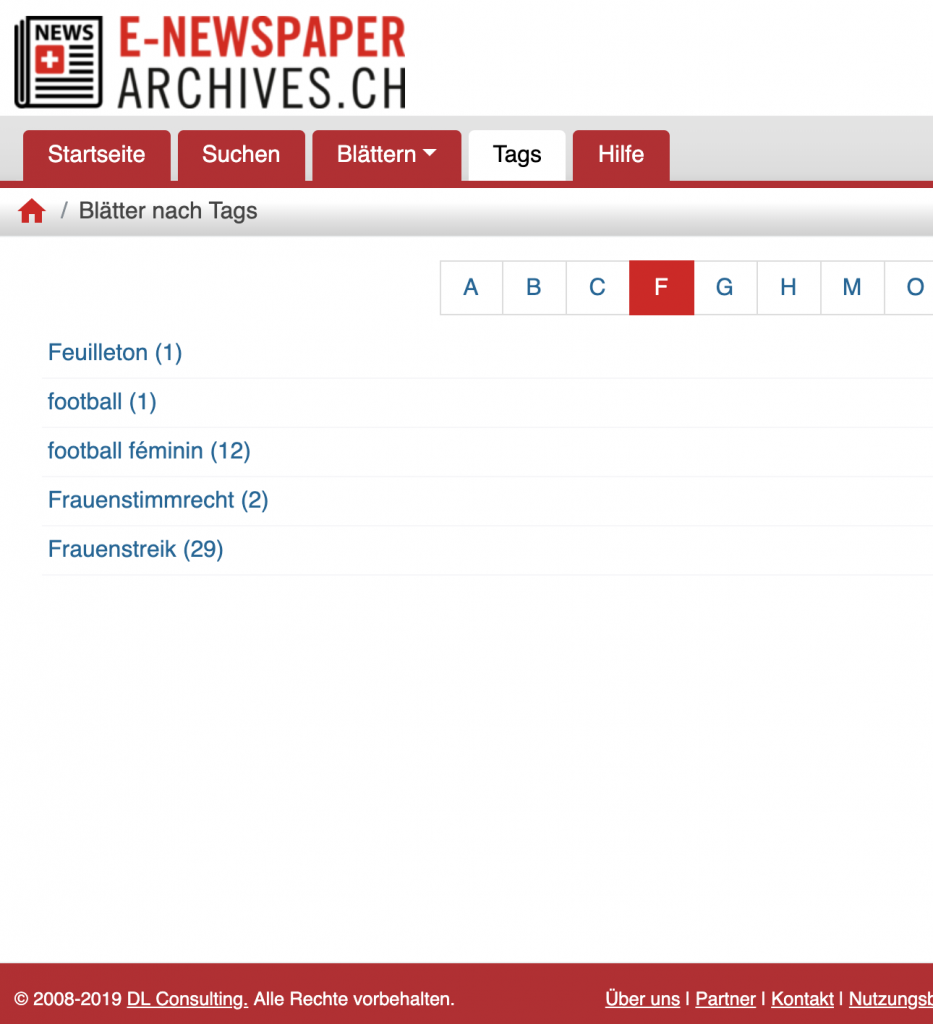
A few interfaces add tags to newspaper titles, such as ANNO:
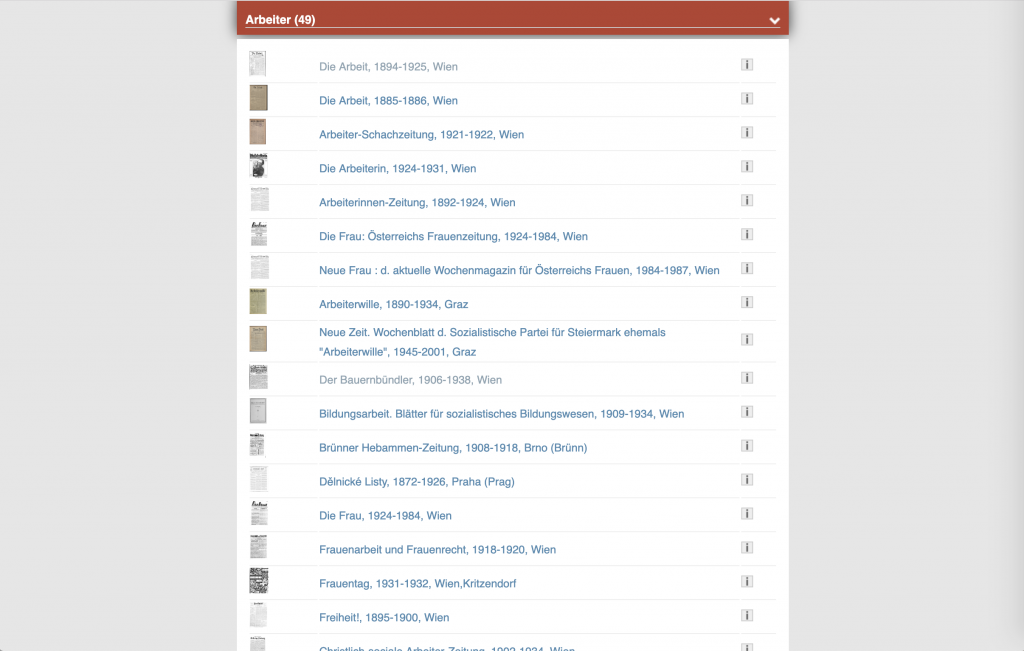
Corpus creation in the digital context and query criticism
Finally, the most important feature for researchers using digitised newspapers is how to collect individual articles and related metadata. As we have seen, the METS/ALTO standards collect all sorts of information about the file, its context and its content. But only a very limited part of this information is easily available to users.
It is often possible to download OCR output and/or the scanned image of the article. On the Scriptorium interface, for example, users can select both the text and the image on a given page and subsequently download them.
Some interfaces offer the option of saving articles or whole issues to a personal account. Very few offer the option to directly interact with digitised collections. These interactions might include an option to correct the OCR or tag articles, as for instance on the Swiss National Library interface.
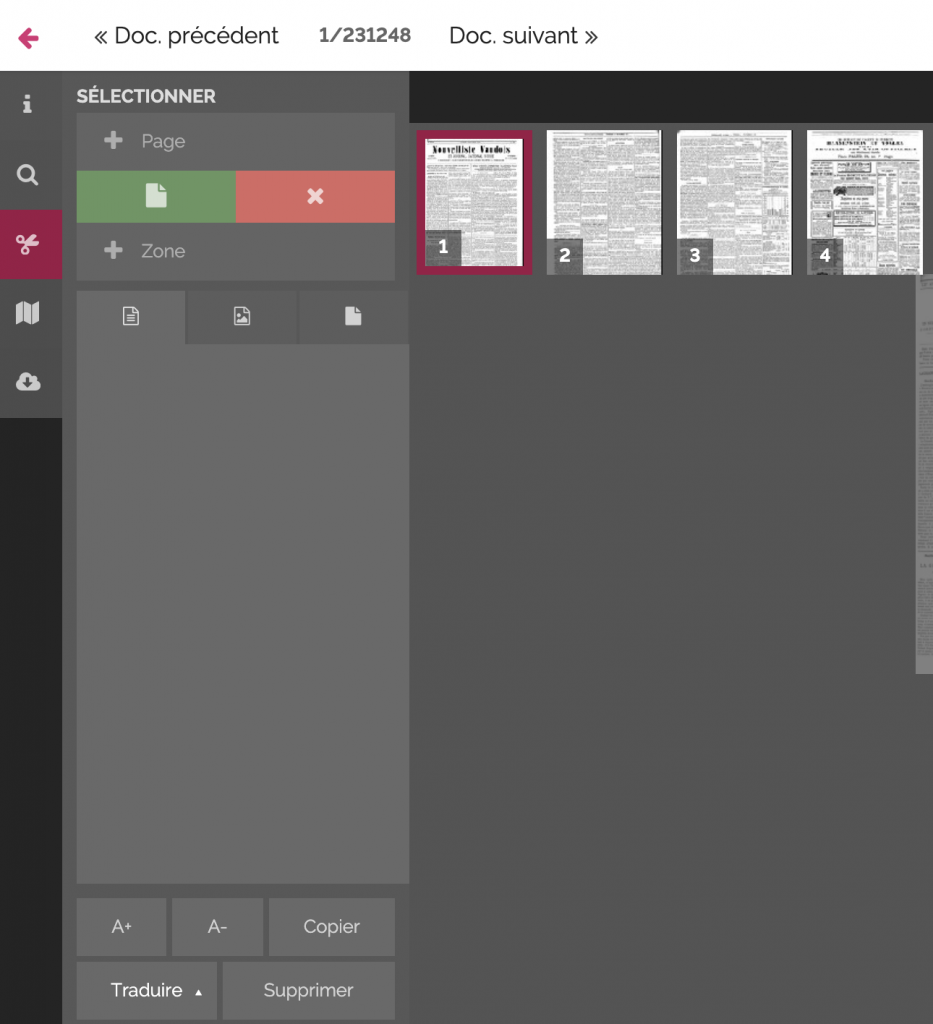
An alternative to downloading is saving collected articles via a stable URL or permalink. This is offered by most of the interfaces produced by national libraries and is a durable way of referencing sources.
But these options remain cumbersome, especially if the research project requires a large collection of individual articles. A few national libraries offer access to an application programming interface (API), limited to copyright-free newspapers, to enable users to formulate queries and download larger datasets.
For instance the Luxembourg National Library (https://data.bnl.lu/) and the Scandinavian national libraries (hosted at https://korp.csc.fi/) have prepared ready-made datasets.
This short overview of the options offered by digitised newspaper interfaces shows how important the design of these interfaces is – and consequently, how important it is to adopt a critical approach to them.
FAQs and documentation
Each library engaging in the digitisation of newspapers has to define the modalities of this digitisation: what level of granularity of detail? Which metadata standard to use? Will the segmentation be at page level or article level? Will there be a separate identification of articles, such as obituaries, advertisement? Each specification adds to the cost of digitisation but it also means it can be later used to create filters on the interface. These specifications are typically conveyed to the company that will perform the digitisation (See for instance the technical requirements expected from the digitisation companies by the Luxembourg National Library : https://data.bnl.lu/data/historical-newspapers/).
Some libraries give some historical information on the collections they built. For instance, Scriptorium presents sub-collections of newspaper titles, a short historical presentation and details of the digitisation process, how the digitisation was financed, or information about the copyright of an item:
Enhanced exploration of digitised newspapers: tools for distant reading and clustering
The obvious added value of digitisation is facilitated access and collection possibilities. At the same time, this yields larger quantities of articles that may be more difficult to deal with. When enhanced with additional processing, digitisation can also open collections up to distant reading, i.e. the search for patterns in large amounts of texts with the help of quantitative methods, and clustering of articles according to this information. Recent efforts focus on the detection of named entities, word embeddings and topics. These options are not yet available on mainstream interfaces provided by institutions such as libraries that we presented previously. Several academic research projects are, however, now undergoing this processing to make the most of the digitised newspaper.
From mentions of people to named entity recognition
Named entities are defined entities that may include people, institutions and locations. The important criterion here is the name – specific named entities need to be differentiated from common nouns. For instance, a pope is a common, generic noun, but Pope Francis is named and therefore identifiable.
Newspapers are typically filled with references to people, institutions and locations. Identifying them and connecting articles that share named entities can help create collections or provide an overview of the themes of the articles.
To enable researchers to use this information, the collections first need to be processed in such a way that named entities are recognised, and these mentions then have to be disambiguated. References to named entities are automatically recognised and collected after an initial annotation of a sample of the collection. The granularity and detail of the annotation is defined beforehand: should all geographical entities by identified as one category or should there be a differentiation between rivers, mountains, etc.? The annotation is then used to train a program to detect any mentions in the digitised collections.
Once the mentions have been detected, then comes the difficult task of disambiguation between variations of names used for a single entity.
See some solutions to these difficulties here: link to the impresso blog on named entity recognition with the example of a query on “Montgomery”: https://impresso-project.ch/news/2018/06/12/tradingzone-ner.html
Search practices in digitised newspaper interfaces:
- ‘Compte Rendu: E-Newspaperarchives.Ch | Infoclio.Ch’. Accessed 2 August 2019. https://infoclio.ch/fr/compte-rendu-e-newspaperarchivesch.
- Crymble, Adam. ‘Digital Library Search Preferences amongst Historians and Genealogists: British History Online User Survey’ 10, no. 4 (2016). http://www.digitalhumanities.org/dhq/vol/10/4/000270/000270.html.
- Ehrmann, Maud. ‘Historical Newspaper User Interfaces: A Review’, 26. Athens, Greece: IFLA, 2019. http://library.ifla.org/2578/1/085-ehrmann-en.pdf.
- Mouhot, Jean-François. ‘Archival Review: ProQuest Historical Newspapers’. Contemporary British History 24, no. 1 (1 March 2010): 131–34. https://doi.org/10.1080/13619460903553867.
Digitised newspaper interfaces:
See the list on Wikipedia:
- ‘Wikipedia:List of Online Newspaper Archives’. In Wikipedia, 31 July 2017. https://en.wikipedia.org/w/index.php?title=Wikipedia:List_of_online_newspaper_archives&oldid=793300648.
Join the Zotero group on Newspapers:
- ‘Zotero | Groups > Digitised Newspapers’. https://www.zotero.org/groups/82589/digitised_newspapers.
Designing digitised newspaper interfaces:
- Moreux, Jean-Philippe. ‘Innovative Approaches of Historical Newspapers: Data Mining, Data Visualization, Semantic Enrichment’, 2016, 17.
- Whitelaw, Mitchell. ‘Generous Interfaces for Digital Cultural Collections’ 9, no. 1 (2015). http://www.digitalhumanities.org/dhq/vol/9/1/000205/000205.html.