

By the end of this section, you will be able to…
- Find and access the available corpora of parliamentary proceedings
- Search through the parliamentary corpora available through concordancers
CLARIN Resource Families
CLARIN for Researchers is an on-line collection of training materials, case studies and expert contacts from the entire CLARIN network, aimed at researchers and students of all stages who are working in the fields of Digital Humanities and Social Sciences and are interested in analysing language data and using text processing tools that are available in the CLARIN infrastructure.
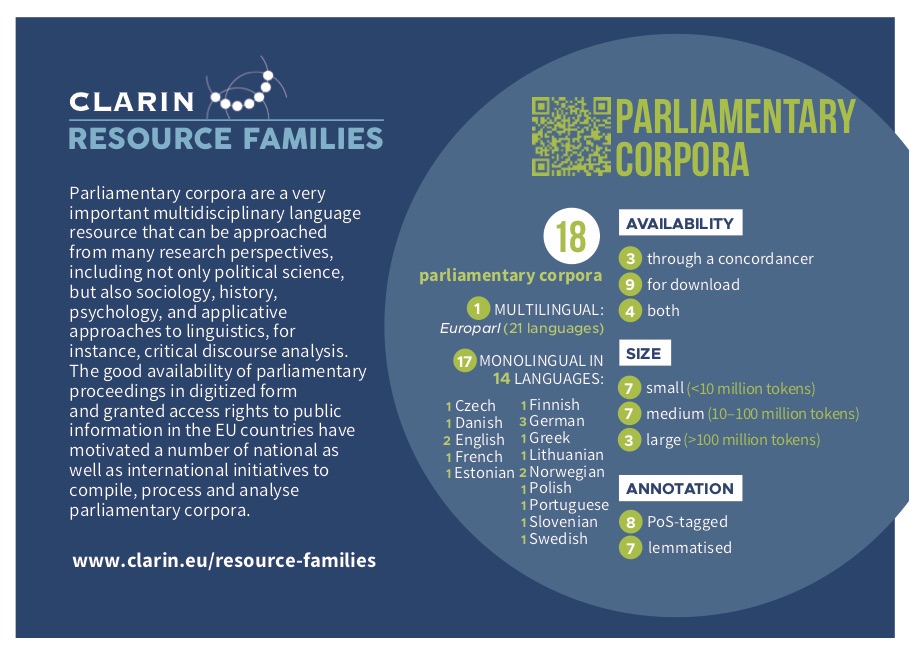
The parliamentary corpora
The CLARIN infrastructure offers access to 18 parliamentary corpora, covering 15 national parliaments and 14 languages, as well as the corpus of the European parliament proceedings, which is available in 21 languages. In the vast majority of cases, the corpora can be directly downloaded from the national repositories or queried through easy-to-use online search environments. They are also richly tagged and mostly available under open licences.
An overview of the existing parliamentary corpora is available at https://www.clarin.eu/resource-families/parliamentary-corpora
Using parliamentary corpora in CLARIN
In this section, we will show how parliamentary corpora can be queried through on line concordancers. As an illustrative example we will use the corpus of the British parliament, called the Hansard corpus. This is the largest parliamentary corpus in the CLARIN Resource Families both in that it covers the longest time period (i.e., the entire 19th and 20th centuries, and a few years in the 2000s) and contains the largest number of proceedings – approximately 7.6 million speeches made by around 40,000 different speakers, which amounts to 1.6 billion tokens. The Hansard corpus is available through the CoCA concordance but other corpora and concordancers are built according to similar principles and can be used in similar ways. We will demonstrate the basic types of corpus queries.

Figure 14. Description of the Hansard corpus in the CLARIN resource families with hyperlinks to the concordance, tools used to annotate the corpus and the key publication about how the corpus was built.
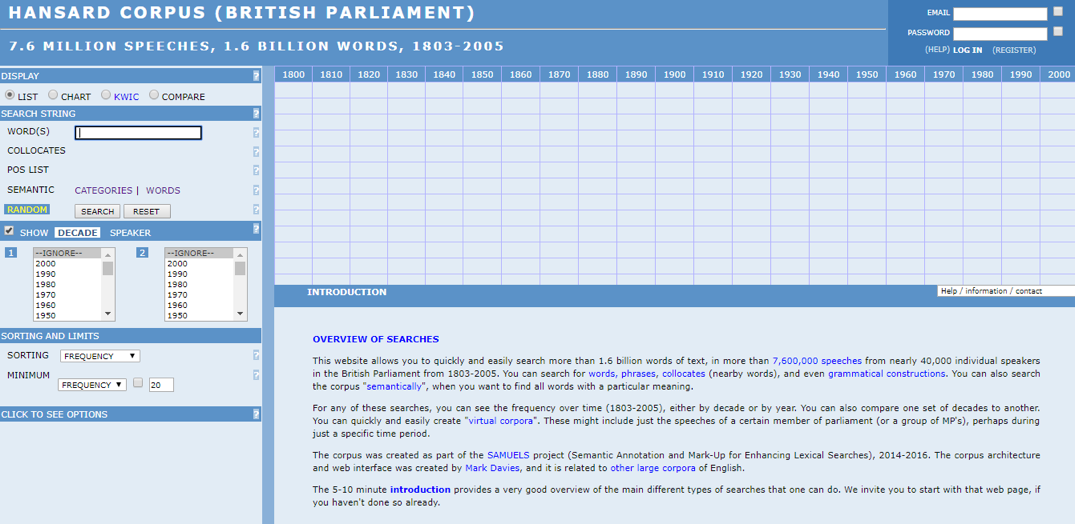
Figure 15. The concordancer for the Hansard corpus.
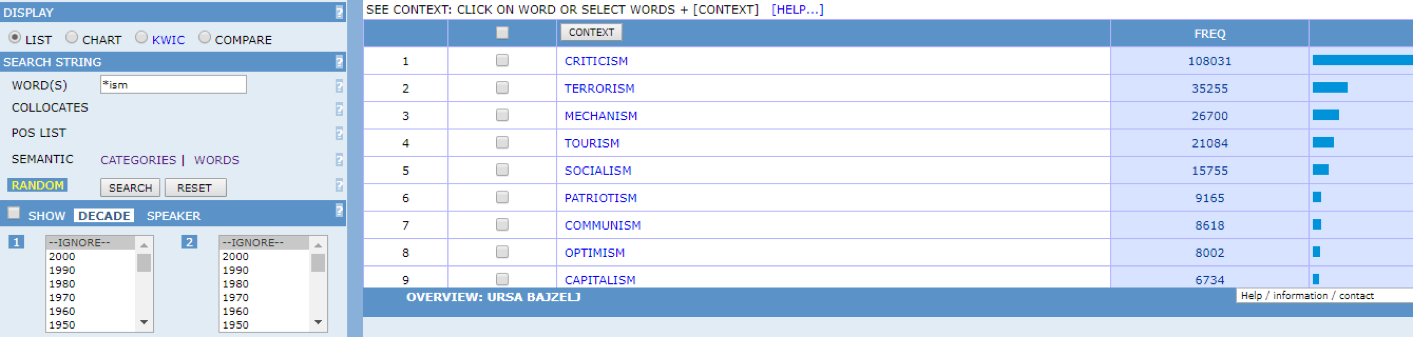
Figure 16. Frequency list for *ism.
Since Hansard is a large diachronic corpus, it is especially suitable for researching how the usage of specific words changed through time in the context of the British parliament. As can be seen in Figure 16, the second most frequent word is terrorism. Let’s say that we want to investigate this word diachronically, using the chart option which sorts all the occurrences of the word either by decade (the default option) or speaker. The chart in Figure 17 shows that the word terrorism has been used in the British parliament since the first half of the 19th century, although it was very infrequent then (for instance, there were 7 uses of the word in the 1850s). The frequency of the word rose dramatically in the 1970s (4846 times compared to 363 instances in the 1960s).

Figure 17. Diachronic chart for terrorism.
Clicking on one of the columns displays the concordances, which show how the word was used in context. Figure 18 shows the first 12 results for the 1970s.
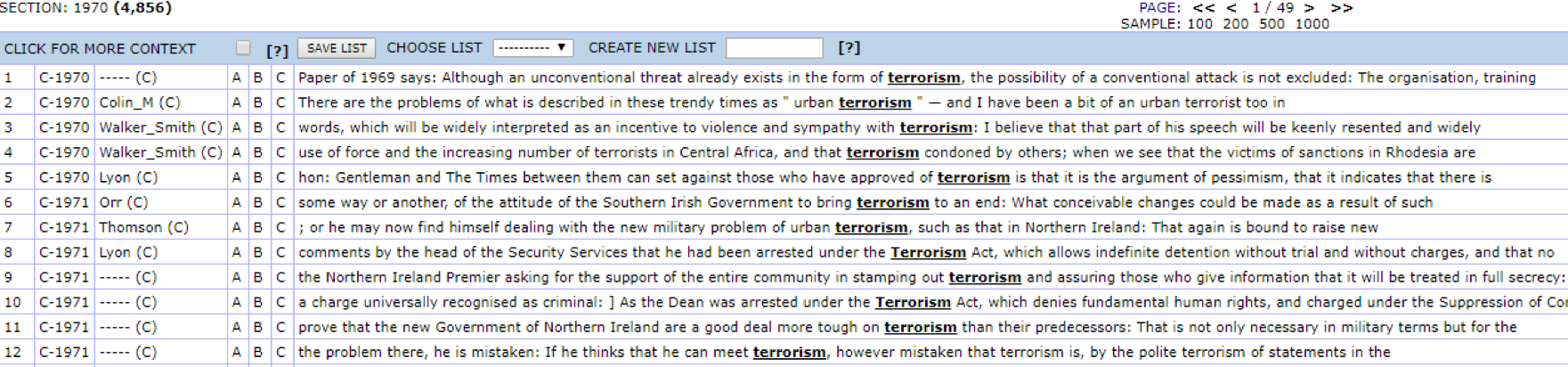
Figure 18. Concordances for terrorism.
Each line is an excerpt of a speech delivered in the British parliament in which the word terrorism was used. The metadata for this entry can be displayed by clicking the MORE CONTEXT tab. Figure 19 shows the metadata for concordance line 6: Orr (C), and allows us to see a substantially more expanded context for the example, including information on the speaker (Mr_Lawrence_Orr), the date (1971_02_15), and the topic of the debate (northern_ireland_hansard_15_february_1971_).
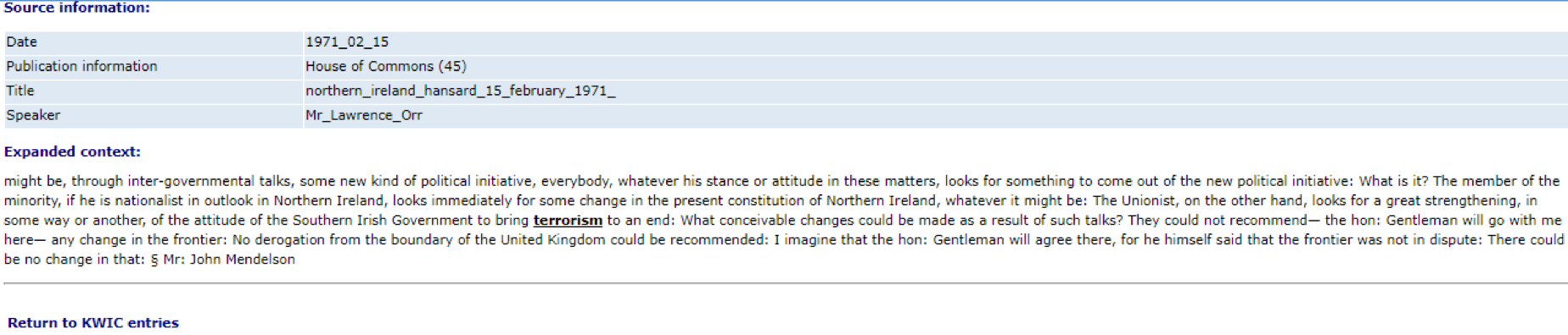
Figure 19. Metadata for one of the concordance lines in the corpus.
Image credits
Figure 14 is taken from Clarin.eu: Parliamentary corpora.
Figures 15-19 are screenshots from the Hansard corpus in the CoCa concordancer.
- Brief tour through CoCA: https://corpus.byu.edu/coca/help/whereStart.asp
- Quick start guide for SketchEngine: https://www.sketchengine.eu/quick-start-guide/
- User manual for Kontext: https://wiki.korpus.cz/doku.php/en:manualy:kontext:index